- 減衰係数と累積報酬
- 制御ポリシー学習では,学習エージェントが累積報酬 Vπ(st)を最大化
するようにすること.
- ただし 0 ≦ γ < 1 で,これを減衰係数 とよぶ(累積報酬を有限の値にするための工夫).
- 累積報酬の最大化と最適な行為
- 状態 s における最適な行為a は,状態
s における累積報酬を最大化する.
- つまり以下の二つの報酬から得られる和 r(s,a) + γV*(δ (s,a))を最大化する.
- r(s,a): 状態 s でアクション a を実行することにより得られる報酬
- Vπ(δ(s,a)): 次状態での最適報酬
- しかし,学習する前のエージェントは Vπ ,r(s,a), δ(s,a) などの関数を知らないことが仮定されている.
- そこで,新しい量として以下のQ値を導入
し,エージェントが行動することによって,環境から
少しずつ与えられるr(s,a) と δ(s,a) に関する情報を使い,Q値の関数近似
を少しずつ形成できるようにする.
- 定義より V*(δ(s,a)) = maxa'Q(δ(s,a), a') であるから,Q値に関する以下の再帰的な定義式を得る.
- Q学習アルゴリズム(以下参照)では,この式を使って観測された(s,a)に対 してQ(s,a)の値を繰り返し計算により逐次近似していく.
- 収束定理
- [定理] Q学習の収束
- 有界の報酬をもつ決定論的MDPにおけるQ学習アルゴリズムが,以下の条件
を満たすとする.
- トレーニング規則 Q'(s,a) ← r + γmaxa'Q'(s',a') を用い る.
- テーブルQ'(s,a)が有界値に初期化される.
- 減衰係数γは 0 ≦ γ < 1 を満たす.
- 各状態・行為のペアが無限回の頻度で実行される.
- n → ∞のとき,すべての s, a, に対してQn'(s,a) → Q(s,a)である.ただし,Qn'(s,a) は Q'(s,a) のn番目の更新であ る.
∞
Vπ(st) = rt + γrt+1 + γ2rt+2 + ・・・ = Σ γirt+i
i=0
Q(s,a) ≡ r(s,a) + γV*(δ(s,a))
Q(s,a) ≡ r(s,a) + γmaxa'Q(δ(s,a), a')
|
|
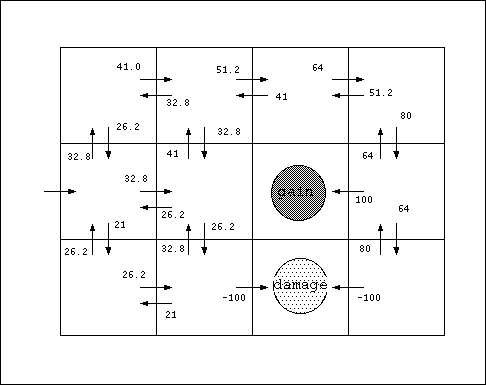
(以前のMDPの例題にQ学習を適用)
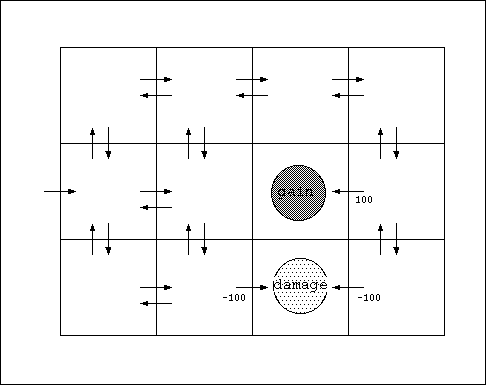
(Q学習が収束した状態)