- MDPとは?
- アクセス可能で不確実な環境において,状態遷移モデルが既知のときに 最適戦略(方策)を計算する問題.
- アクセス可能とは? エージェントが動作選択に必要な環境情報をセンサを通して完全に知覚できること?
- マルコフ性とは? 与えられた状態からの状態遷移確率が現在の状態に依存し,それまでの履歴に依存しないこと.
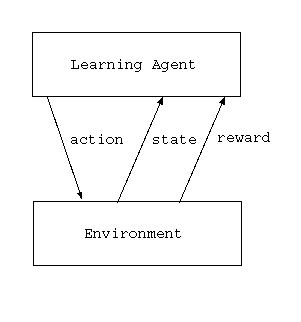
- 強化学習の環境
- MDP では以下が規定されている.
- エージェントは環境の状態集合 S(有限) を知覚する
- アクション集合 A(有限) を環境に対して遂行できる
- 2の結果,環境から報酬を受取る
- 時間軸として離散時間を用いる
- 状態,行為,報酬の規定
- 表記および定義
- 関数δとrは環境の一部と考え,必ずしもエージェントに知られていないと仮定.
- δ(st, at) とr(st, at)は現在の状態 (st)と現在の行為(at) に依存し,それ以前の状態や行為には依存しないと仮定.
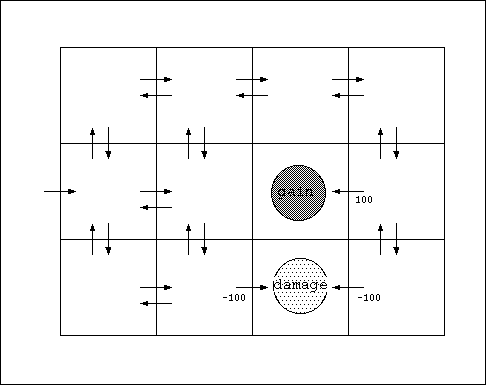
- MDPの例とエージェントのタスク
- エージェントのタスク: この世界で報酬を最大化する行動系列 (現在の観 察された状態 stに基づいて行為 atを決めるための 制御ポリシーπ(st) = at を学習すること.
(MDPの例)