- 目的
- あらかじめ分類しておいたデータ集合の法則性を推定し,決定木を自動的に生成すること. >
- 決定木
- 属性・属性値ペアのリストとして与えら れるデータを受取り,それをあらかじめ定められた概 念(カテゴリ)のどれに属すかを決定する装置
- (注意) ここでは,簡単のためにあらかじめ与えられた一つの概念に
属すかどうかを決定する装置とする.つまり,決定木はブール関数をあらわ
すこととする.
- テストの結果が n 通りあるときは,それぞれの結果に対して n 個のアー クをもつ.
- 各中間ノードにおけるテストとしては唯一の属性値の検査だけが許され る.
[葉ノード]: 概念 (ここではブール値) [中間ノード]: 属性値のテスト - 決定木の良さ
- 一般に同じ判別をする決定木は多数ある.
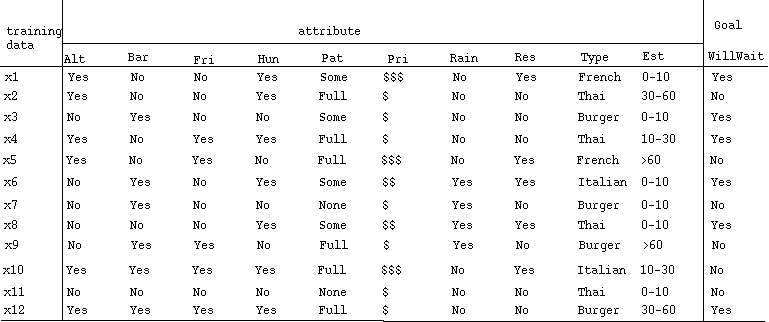
(トレーニングデータの例)
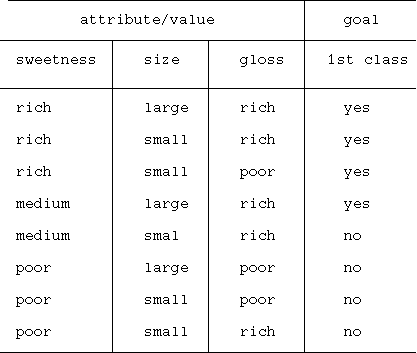
このトレーニングデータと整合する決定木は,上記の例2以外にも以下のよう なものがある.
(決定木の例3)
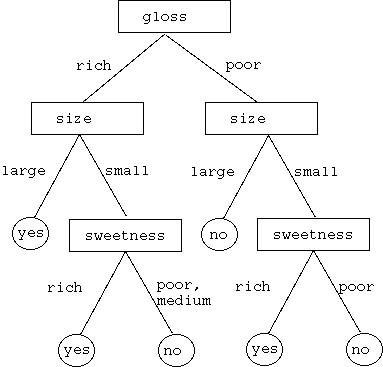
(決定木の例4)
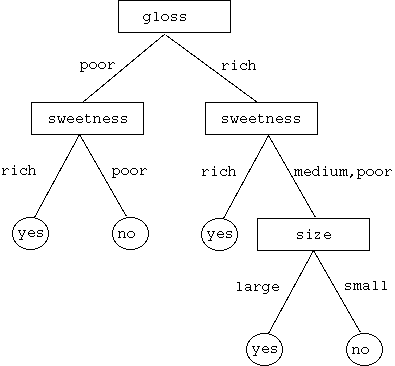
- では,どの決定木がよいのか?
- ⇒ 直感的には構造の簡単な決定木がよい
- 一般に,与えられたデータと整合する仮説のなかで最も単純なものを優先 する原則はオッカムの剃刀 (Ockham's razor)と 呼ばれる.この場合は何が使えるか?
- レストラン問題の例
- いくつかの属性のテストによる例の分割
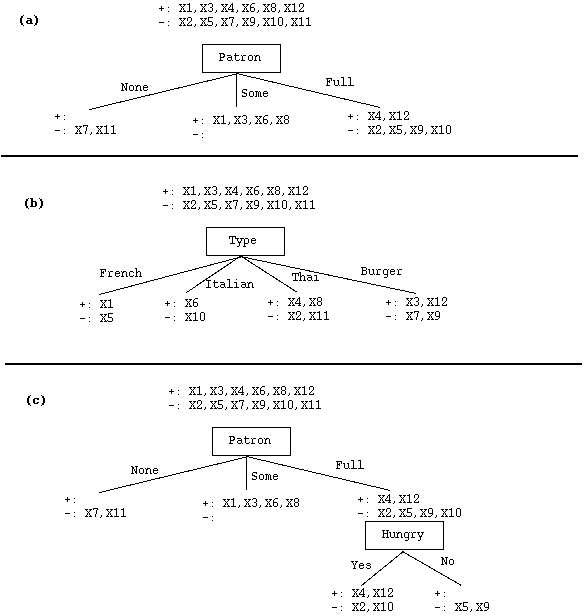
- (a) からPatronsはかなり重要な特性であることがわかる
- (b) はTypeが重要でない属性であることを示している
- 情報理論(エントロピー)の利用
- 情報エントロピーの定義(種々の事象の情報量(以下の -logPの項)にそれらの事象の
生起確率で重み付けした平均情報量)
n I(P(x1), ..., P(xn)) = Σ -P(xi)logP(xi) i=1 - 決定木の学習にとって答えるべき質問は「与えられた例に対する正しいク
ラス(カテゴリ)は何か?」である.正しい決定木はこの質問に対して正しく解
答する.
- いかなる属性もテストされる前の可能な各答の確率の推定値は,トレー
ニングデータの正負の例の比率によって与えられる.
- トレーニングデータが p 個の正例と n個の負例から成り立っているとす る.そのとき,正しい答えに含まれる情報量の推定値は以下で与えられる.
I(p/(p+n), n/(p+n)) = -(p/(p+n))log(p/(p+n)) - (n/(p+n))log(n/(p+n))
- レストランの例の場合のトレーニングデータの場合,p = n = 6 なので, 1ビットの情報を必要とする.
- トレーニングデータが p 個の正例と n個の負例から成り立っているとす る.そのとき,正しい答えに含まれる情報量の推定値は以下で与えられる.
- Gain(属性テストによる情報量とテスト後の必要情報量の差)
- 単一の属性Aは通常多くの情報を与えないが,そこで与えられた情報量を 属性テストの後でさらにいくらの情報量が必要である かを調べることで正確に計ることができる.
- [準備]
任意の属性Aはトレーニングデー タ E を A に対する値によって部分集合 E1, ..., Ev に分割する.ここで,A は v 個の異なった値を持つ.各部分集合 Ei は pi 個の正例と ni 個の負例を持つ.
もし次にこの枝に進むと,質問に答えるためにさらに I(pi/(pi+ ni), ni/(pi+ ni))ビットの情報量を必要とす る.
ランダムに抽出された例は,その属性の i 番目の値を取る確率は (pi + ni)/(p + n) であるので,属性 A のテスト後, 平均すれば例を分類するのにv Remainder(A) = Σ((pi+ni)/(p+n))*I(pi/(pi+ni), ni/(pi+ni)) i=1ビットの情報量を必要とする.属性テストによる情報量とテスト後の情報量の 差(ゲイン)は,以下のように定義される.Gain(A) = I(p/(p+n),n/(p+n)) - Remainder(A)
- 以下に述べる決定木の学習アルゴリズム ID3 では,上記のGainが最大利 得となる属性を選ぶ.
- 決定木学習アルゴリズム ID3
- ID3は再帰的に適用される.ある属性テストが何かを分割した後で,各分
割結果はそれ自身,少ない例と一つの少ない属性からなる新たな決定木学習問
題となる.この再帰問題には以下の4つの場合が存在する.
- もし正例と負例が混ざっていれば,それらを分けるのに可能な属性の
Gain を計算することで最良の属性を選択する.(レストランの例題の(c))
- もし残った例がすべて正例(あるいは負例)であれば終了.アルゴリズム
は Yes (あるいは No) を答えることが出来る.(レストランの例題の(c)の
None あるいは Some の場合)
- もしも例がまったくなければ,そのような例がまったく観測されなかっ
たことを示している.その場合,その節の親の最大多数となるクラスをデフォ
ルト値としてその節に割り当てる.
- もし属性が残っていなくて,しかも正負の例が共に存在すれば問題.
これは,これらの例がまったく同じ記述を持ちながら異なるクラスに属してい
ることを意味する.データに誤りがある場合にこれがおこる.
(レストランの例におけるID3による学習により得られ た決定木)
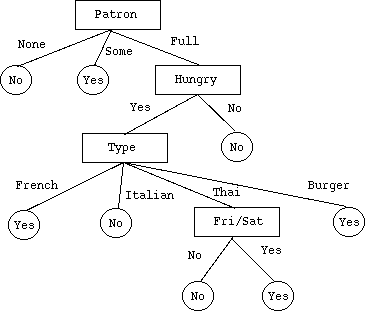
- もし正例と負例が混ざっていれば,それらを分けるのに可能な属性の
Gain を計算することで最良の属性を選択する.(レストランの例題の(c))
(決定木の例1: 卒業の判定)
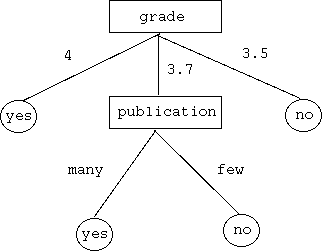
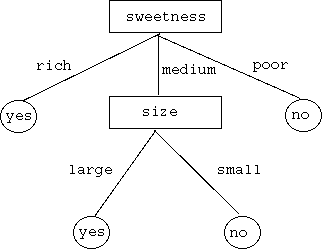
(決定木の例2: みかんの上/並の判定)